
知识概念
一、什么是Lucene?
Lucene是apache软件基金会jakarta项目组的一个顶级子项目,因为它不是一个完整的搜索引擎,而是一个具有全文检索引擎的架构,提供了完整的查询方法、索引引擎和部分文本分析的引擎,所以它是一个全文搜索引擎的工具包。Lucene的目的是提供一个简单、易用的便于开发的工具包,以方便开发人员实现全文检索的功能,或者是以其为基础建立一个完整的全文检索系统。
作为apache的一个开源项目,Lucene自从问世之后,就深受广大用户群体的喜爱,程序员们不仅可以使用它来构建具体的全文检索应用,而且还可以将它与各种系统软件相结合,以及用其搭建Web应用,甚至某些商业软件也采用了Lucene作为其全文搜索的核心
二、Lucene的优势
(1)索引文件格式像java语言一样可以独立于各个平台。因为Lucene规定了一套以8位字节为基础的索引文件格式,使得不同平台的应用都能够使用索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,即可以对新的数据创建新的小索引文件,提升检索速度。最后通过和已有的索引库文件合并,从而达到优化的目的。
(3)Lucene可以扩展已有的关键词库,即可以通过需求将所需词组扩展到Lucene中
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)Lucene底层已经实现了大部分的检索功能,已经可以满足需求,用户只需要调用方法即可获得强大的搜索能力,Lucene的检索默认实现了一些操作如布尔操作、模糊查询(Fuzzy Search)、分组查询等等
三、知识梳理
使用Lucene开发应用,首先必须先理解几个重要的概念,分别是analyzer、field、document、term、tocken。 (1) analyzer中文意思是分词,它的作用是将域中的文字按照某种规则切割成若干个关键字,后期检索就是通过匹配关键字来进行的。 Lucene自带了几个分词器,这些都对中文分词不是很理想,所以就需要扩展其他的分词器如IK分词器。(2) field指的是域, Lucene按照你的需求进行区域划分,将分词后的数据放入相应的域中,它的作用是用户可以通过指定某个域来进行范围查询。域有两个属性:储存和索引。通过对储存属性的设定可以为该域是否储存即此域的数据是否可以显示;对索引属性的设置可以规定该域的数据是否分词。
(3) document表示的是文档,文档可以包含一个域也可以包含多个域,每个文档的域可以相同也可以不同。数据源中的每一行记录表示就是一个文档。可以通过关键字匹配查询到相应的文档id,通过文档id可以获得文档中的域的信息从而达到检索的目的。
(4) term指的是检索的最小单元即分词后的关键字,term由两部分组成:关键字文本和这个关键字所在的域。
(5) tocken表示的是term的一次出现,它包含term文本和相应的起止偏移,以及一个类型字符串。一句话中可以出现多次相同的词语,它们都用同一个term表示,但是用不同的tocken,每个tocken标记该词语出现的地方。
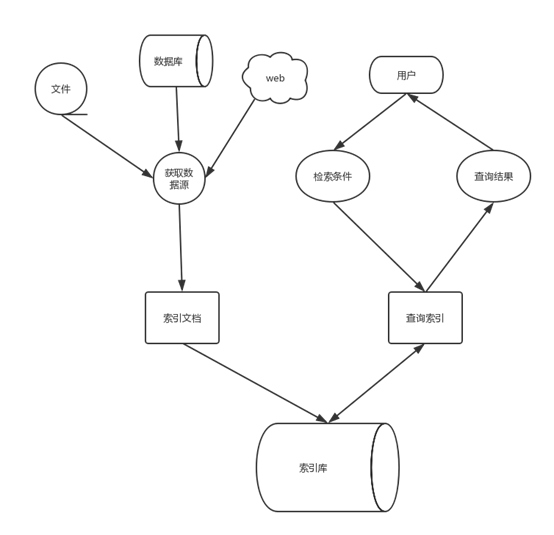
使用Lucene开发应用的流程如下图。它的流程分为两部分:第一部分是建立索引库,即先是需要获取数据,然后将数据划分到指定域中,对域中的数据进行分词,并将每条记录添加到文档中,最后通过这些文档组成了索引库。第二部分是用户使用的时候产生,用户编写好查询条件,lucene分析查询条件然后到索引库中去检索,最后将数据结果展示给用户。
四、示例
框架:Springboot; (易白教程) Pom.xml
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>7.3.1</version>
</dependency>
public class IndexUtils {
private static Logger logger = Logger.getLogger(IndexUtils.class);
List<Document> doList = null;
Document document = null;
IndexSearcher searcher = null;
IndexWriter writer = null;
IndexReader reader = null;
IndexWriter ramWriter = null;
public static Analyzer analyzer;
static Directory fsd;
static Path path;
// 静态资源加载,当类加载的时候运行(因为只要加载一次)
static {
logger.info("lucene初始化");
try {
// IKAnalyzer中文分词器(可扩展)
// 标准分词器:Analyzer analyzer = new StandardAnalyzer();
// new IKAnalyzer(true)表示智能分词
// new IKAnalyzer(false)表示最细粒度分词(默认也是这个)
analyzer = new StandardAnalyzer();
path = Paths.get("mysql/keyword");// 磁盘索引库路径(相对路径)
fsd = FSDirectory.open(path);// 创建磁盘目录
} catch (IOException e) {
logger.error("lucene初始化发生IOException异常");
e.printStackTrace();
}
}
/**
* 采集数据
*
* @throws IOException
*/
public void creatIndex() throws IOException {
// 分词
doList = analyze();
// lucene没有提供相应的更新方法,只能先删除然后在创建新的索引(耗时)
// 由于IndexWriter对象只能实例化一次如果使用内存和磁盘想结合的方式则需要两个IndexWriter故行不通
// 虽然创建的时候耗时但是这样使得文件只有6个 ,搜索时减少了一些io操作加快了搜索速度
writer = deleteAllIndex();
for (Document doc : doList) {
writer.addDocument(doc);
}
writer.commit();
writer.close();
}
/**
* 分词,工具方法
*
* @throws IOException
*/
public List<Document> analyze() throws IOException {
doList = new ArrayList<Document>();
File resource = new ClassPathResource("mysql.txt").getFile();
BufferedReader reader = new BufferedReader(new FileReader(resource));
String keyword = null;
while( (keyword=reader.readLine()) != null){
document = new Document();
Field mysql = new TextField("keyword", keyword, Store.YES);
document.add(mysql);
doList.add(document);
}
if(reader != null){
reader.close();
}
return doList;
}
/**
* 删除索引库
*
* @throws IOException
*/
public IndexWriter deleteAllIndex() throws IOException {
writer = getWriter();
writer.deleteAll();
return writer;
}
/**
* 获取搜索器
*
* @param reader
* @return
* @throws IOException
*/
public IndexSearcher getIndexSearcher() throws IOException {
if (null == searcher) {
reader = DirectoryReader.open(fsd);
searcher = new IndexSearcher(reader);
}
return searcher;
}
/**
* 获取磁盘写入
*
* @return
* @throws IOException
*/
public IndexWriter getWriter() throws IOException {
if (null == writer) {
// 为什么使用这种new匿名方式创建该对象 IndexWriterConfig(Version.LUCENE_4_10_3,
// analyzer)
// 因为IndexWriterConfig对象只能使用一次、一次、一次
writer = new IndexWriter(fsd, new IndexWriterConfig(analyzer));
}
return writer;
}
/**
* 工具方法
*
* @param query
* @param num
* @return List<Document>
* @throws IOException
*/
public static List<Document> searchUtil(Query query, IndexSearcher searcher) throws IOException {
List<Document> docList = new ArrayList<Document>();
TopDocs topDoc = searcher.search(query, Integer.MAX_VALUE);
ScoreDoc[] sd = topDoc.scoreDocs;
for (ScoreDoc score : sd) {
int documentId = score.doc;
Document doc = searcher.doc(documentId);
docList.add(doc);
}
return docList;
}
/**
* 给查询的文字上色
*
* @param query
* 查询方法
* @param analyzer
* 分词器
* @param fieldName
* 域名
* @param fieldContent
* 查询内容
* @param fragmentSize
* 文字结果截取的长度
* @return
* @throws IOException
* @throws InvalidTokenOffsetsException
*/
public static String displayHtmlHighlight(Query query, Analyzer analyzer, String fieldName, String fieldContent,
int fragmentSize) throws IOException, InvalidTokenOffsetsException {
// 创建一个高亮器
Highlighter highlighter = new Highlighter(new SimpleHTMLFormatter("<font style='font-weight:bold;'>", "</font>"),
new QueryScorer(query));
Fragmenter fragmenter = new SimpleFragmenter(fragmentSize);
highlighter.setTextFragmenter(fragmenter);
return highlighter.getBestFragment(analyzer, fieldName, fieldContent);
}
}
public class SearchMethod extends IndexUtils{
List<Document> docList = null;
/**
* 通过lucene最小单元term进行查询
* @return
* @throws IOException
*/
public List<Document> searchByTermQuery(Term term) throws IOException{
searcher = getIndexSearcher();
Query query = new TermQuery(term);
docList = searchUtil(query,searcher);
return docList;
}
/**
* 前缀查询
* @param term
* @return
* @throws IOException
*/
public Map<List<Document>,Query> searchByPrefixQuery(Term term) throws IOException{
Map<List<Document>,Query> map = new HashMap<List<Document>,Query>();
searcher = getIndexSearcher();
Query query = new PrefixQuery(term);
docList = searchUtil(query,searcher);
map.put(docList, query);
return map;
}
/**
* 智能提示
* @param pageIndex
* @param pageSize
* @param field
* @param content
* @return
* @throws ParseException
* @throws IOException
*/
public List<String> suggestion(String field,String content) throws ParseException, IOException{
List<String> strList = new ArrayList<String>();
QueryParser qp = new QueryParser(field, analyzer);
Query query = qp.parse(content);
searcher = getIndexSearcher();
TopDocs topDoc = searcher.search(query, Integer.MAX_VALUE);
ScoreDoc[] sd = topDoc.scoreDocs;
for (ScoreDoc score : sd) {
int documentId = score.doc;
Document doc = searcher.doc(documentId);
String str = doc.get(field);
strList.add(str);
}
return strList;
}
/**
* QueryParser 会对输入的语句进行分词然后查询
* @return
* @throws ParseException
* @throws IOException
*/
public Map<List<Document>,Query> searchByQueryParser(String field,String content) throws ParseException, IOException{
Map<List<Document>,Query> map = new HashMap<List<Document>,Query>();
QueryParser qp = new QueryParser(field, analyzer);
Query query = qp.parse(content);
searcher = getIndexSearcher();
map.put(searchUtil(query,searcher), query);
return map;
}
/**
* 多域、多条件查询
* @param fields 域数组
* @param queries 查询数组
* @param flags 域之间的关系
* @return
* @throws ParseException
* @throws IOException
*/
public List<Document> searcherByMultiFieldQueryParser(String[] fields,String[] queries,Occur[] flags) throws ParseException, IOException{
Query mfQuery = MultiFieldQueryParser.parse(queries, fields, flags, analyzer);
searcher = getIndexSearcher();
docList = searchUtil(mfQuery,searcher);
return docList;
}
}
三、总结
lucene是一个健全的工具包,我们可以通过它来构建一个完整的检索系统。